|
|

|
Documentation As part of computer vision and biometrics team at RBS, I had a chance to experiment with the state of art biometrics and face analytics. Insipired from same I have made cetrain efforts to open source solution to a problem that I inititally encountered while starting the innovation project at RBS of having a onestop shop solution for all the face recogntiion tasks such as detection, recogntion, alignment, landmark detection and verficiation. The current project aim is to provide multi viewpoint invaraint detection and landmark detection that can help in better recognition on devices in real time. The algorithm is lightweight and is designed to be able to produce near real time FPS on CPU and therefore, is edge compute compatible i.e. can run on hardware with computing power constraints. |
|
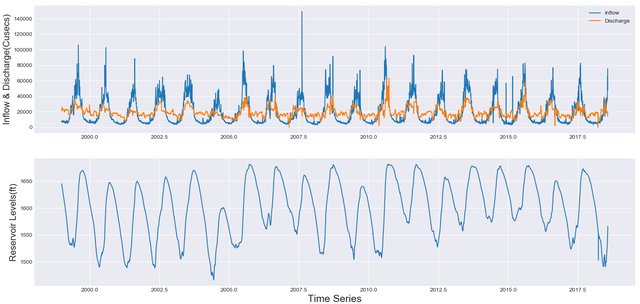
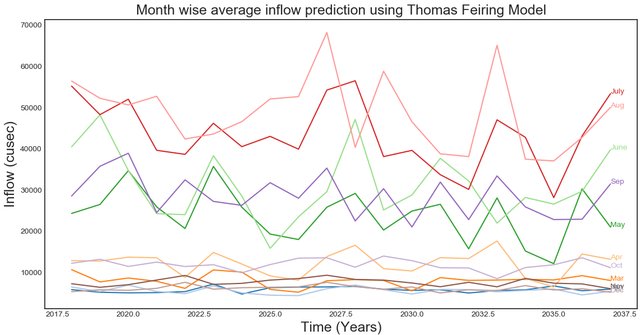
This work proposes a LSTM model for daily inflow determination and a naive anomaly detection algorithm base-line using LSTM. In other words a strong baseline to predict floods and droughts for any prediction model. Experiments to prove the efficacy of LSTM for inflow prediction are done on corpus of daily inflow data of past 20 years for Bhakra Dam. Although, experiments are run on data from Bhakra Dam Reservoir in India, LSTM model and anomaly detection algorithm are general purpose and can be applied to any basin with minimal changes. |

|
Use of DL for transliterated text launguage identfication. This work aimed to identify text based content written in roman script which conveys meaning in Hindi language. The project proposes a methodology to identify language based on semantic meaning of the text. The model was tested and propsed with novel features for Hindi, for a corpus of ~10 k lines of transliterated Hindi text scraped from web |

|
An artificial intelligence for the 2048 game based on expectiminmax algorithm |
.png) .png)
|
report, Project Website There are multiple aspects and areas of problems to solve to make DNA storage commercial. Why are excited about storing information in DNA? How many of us can read the floppy drives now? Its very hard to read them becuase the equipments available to read them are hard to find now. We shift our storage medium iteratively copying the information. But no method of storage is currently long term. The current storage systems shall render themselves redundant soon. So what is the solution? DNA at its worst has a half life of over 500 years and DNA data from over 50k years of unattended fossils have been successfully sequenced. With more than 90% of data being generated in past no matter how much horizontally we scale our servers data will increase exponentially. Therefore the solution to offer to such massive data storage crisis is to find a media that can store huge amount of data in lot less space. Again we find DNA to be the answer. |
{kind=link}
|
|